TT-Forge™
TT-Forge is Tenstorrent’s MLIR-based compiler stack that lets you compile, optimize, debug, and extend models.
Now in public beta, TT-Forge is yours to shape. Pitch a feature, prototype it, or grab a bounty.
Engineered for Innovation
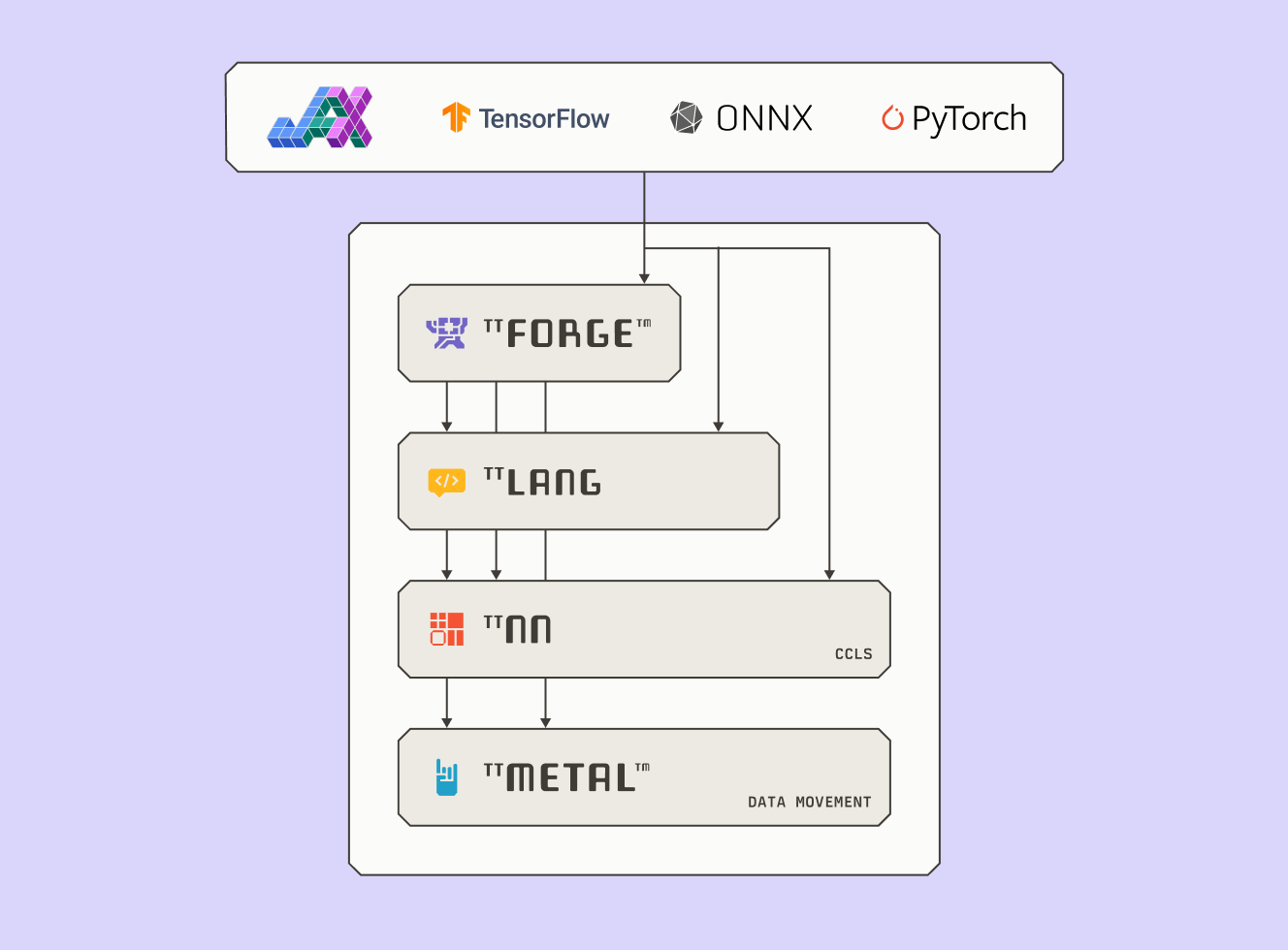
Designed for open-source flexibility, TT-Forge connects with OpenXLA, MLIR, ONNX, TVM, PyTorch, and TensorFlow. TT-Forge offers a modular foundation for pushing AI workloads on custom silicon. It lowers models into optimized IRs for execution on TT-NN and TT-Metalium, Tenstorrent’s low-level AI hardware SDK.
Why MLIR?
MLIR is modular, extensible, and enables multi-level abstraction. It spans multiple frameworks, supports custom dialects, and handles everything from AI to HPC. Thanks to MLIR’s flexible design, TT-Forge can quickly adopt new ops, frameworks, and hardware targets. As the MLIR ecosystem expands, TT-Forge evolves right alongside it.

Bring Your Model from Anywhere* (almost)
TT-XLA
Multi-chip projects with JAX and PyTorch
TT-XLA is Tenstorrent’s PJRT-based bridge for compiling and running models from JAX and PyTorch on Tenstorrent hardware. It supports just-in-time (JIT) compilation through StableHLO, feeding into TT-MLIR for optimized execution.
With native support in JAX and integration through PyTorch/XLA, TT-XLA compiles models to run on Tenstorrent hardware—with minimal changes to your existing code and support for multi-chip execution.
TT-Forge-ONNX
Single chip projects with ONNX and TensorFlow
TT-Forge-ONNX is Tenstorrent’s framework agnostic frontend that’s designed to optimize and transform computational graphs for deep learning models. Powered by TT-TVM, it supports the ingestion of ONNX, TensorFlow and similar ML frameworks–making it easier to bring your models to Tenstorrent hardware efficiently.
Features

Performance
Optimized compilation and custom dialects (TTIR, TTNN, TTKernel) enable efficient execution, maximizing inference performance on Tenstorrent hardware. Simplified performance optimization via tt-explorer.

Hardware-Aware Compilation
TT-Forge™ doesn’t just compile models – it understands the hardware they run on. With custom dialects like TTIR and a compiler stack built around TT-MLIR, it’s optimized for Tenstorrent’s architecture, resulting in high utilization, efficient memory access, and scalable performance across chips.

Tools
Tenstorrent’s toolchain simplifies ML model compilation, optimization, and execution on Tenstorrent hardware. Key tools include: TT-Blacksmith (ready-to-run training examples), TT-Explorer (a visual performance analyzer for models), and TT-NPE (a network-on-chip (NoC) simulator and profiler).